엑셀 / 중복된 값 찾는 방법, 중복 항목 제거하는 방법
엑셀로 자료를 취합하고 정리하다보면 중복된 값들이 생기기도 합니다. 그런 중복 항목을 찾기 위해 눈으로 검토할 필요는 없습니다. 엑셀에는 중복된 항목을 찾거나, 찾아서 제거하는 기능이 있기 때문입니다.
중복 값 찾기
- 중복 값을 찾을 열을 선택합니다.
- [홈 - 조건부 서식 - 셀 강조 규칙 - 중복 값]을 클릭합니다.
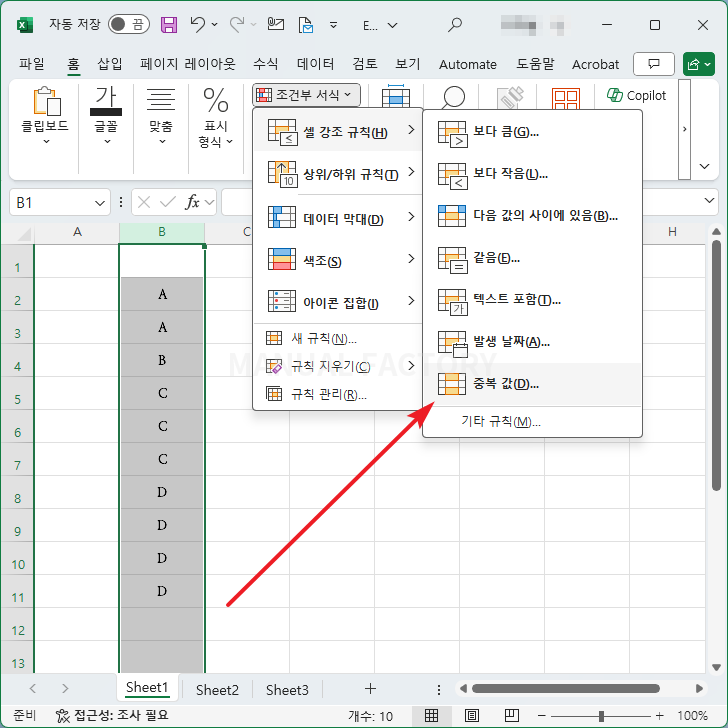
- [확인]을 클릭하면...
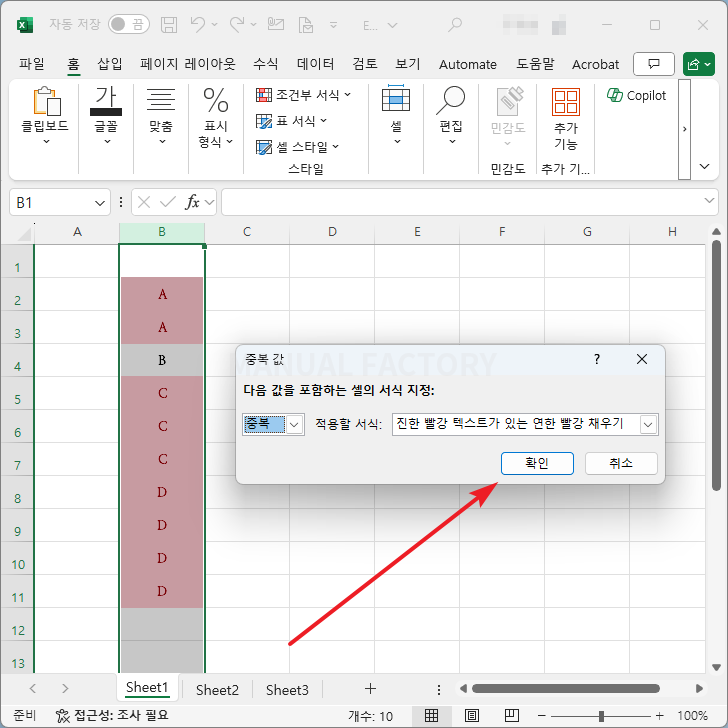
- 중복된 값이 강조됩니다.
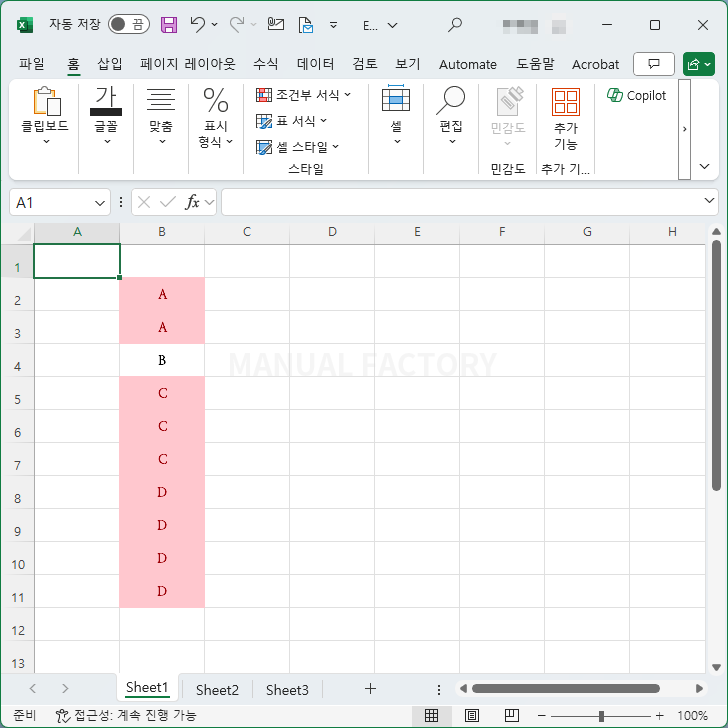
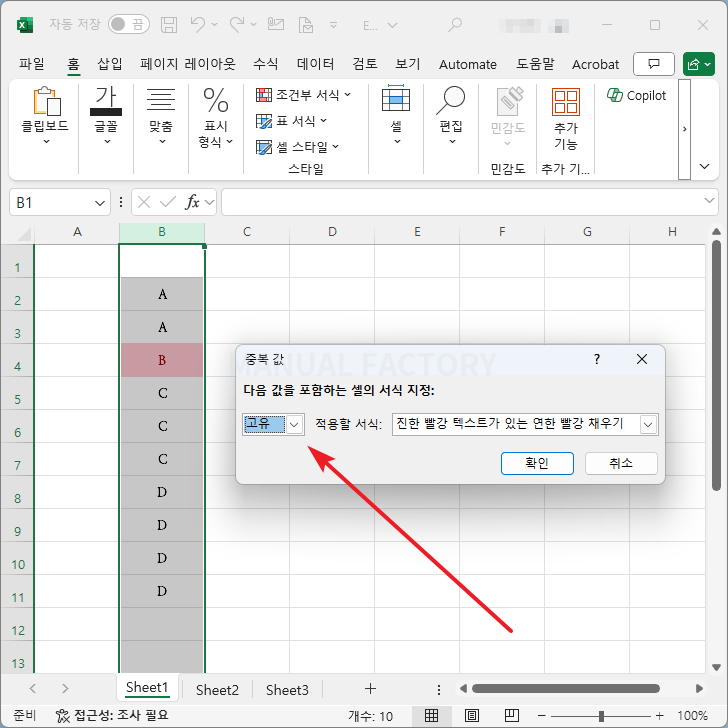
- 조건부 서식에서 [중복] 대신 [고유]를 선택하면, 중복되지 않은 값만 강조됩니다.
중복된 항목 제거
하나의 열에서 중복된 항복 제거
- 다음과 같은 데이터가 있다고 할 때...
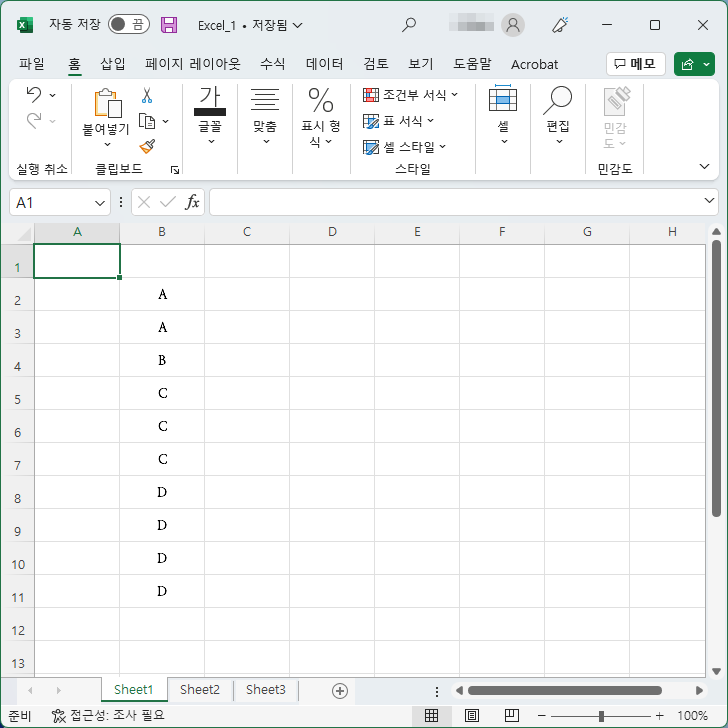
- 열을 선택하고 [데이터 - 데이터 도구 - 중복된 항목 제거]를 클릭합니다.
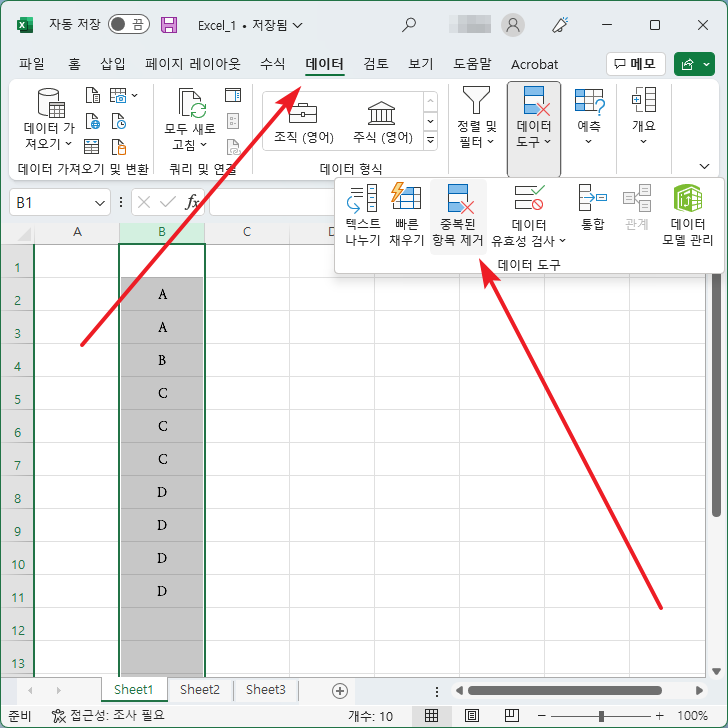
- [확인]을 클릭하고...
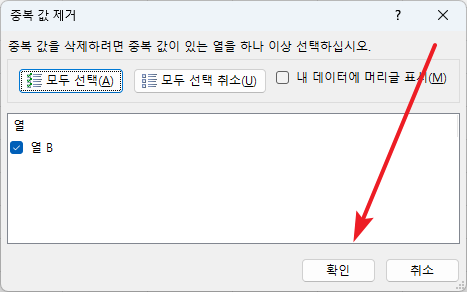
- 다시 한 번 [확인]을 클릭하면...
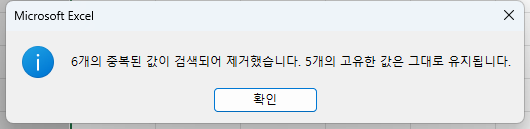
- 고유값 하나씩만 남기고 다 사라집니다.
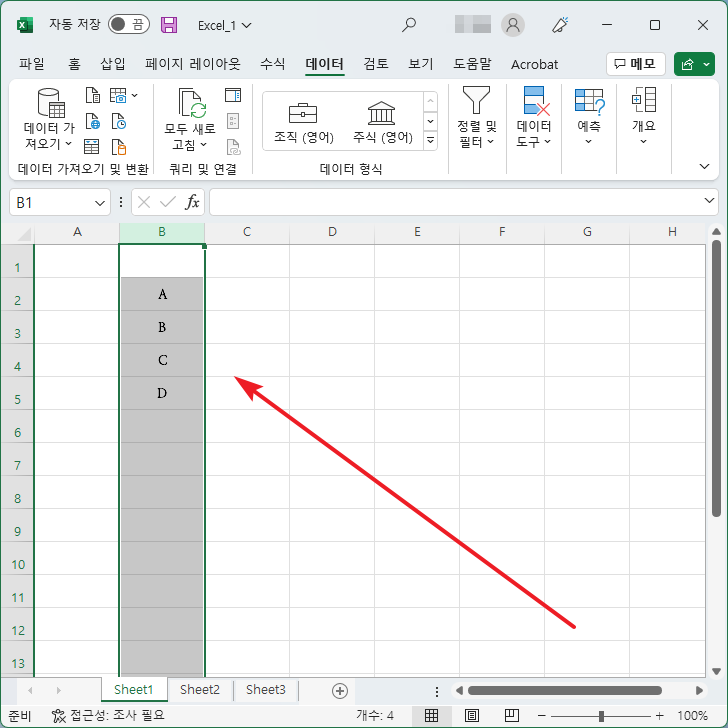
여러 열에서 중복된 항목 제거
- 여러 개의 열을 선택하고 [중복된 항목 제거]를 클릭합니다.
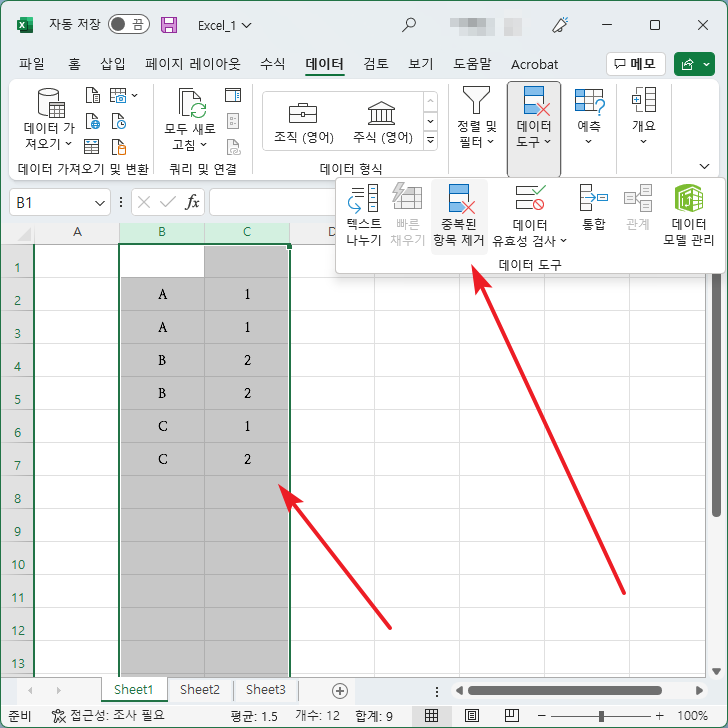
- [확인]을 클릭하고 계속 진행하면...
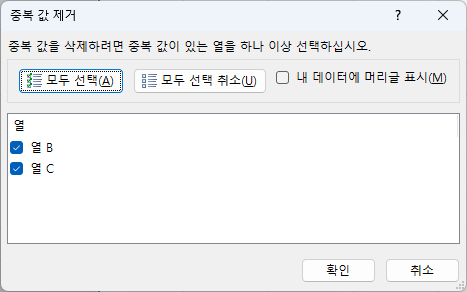
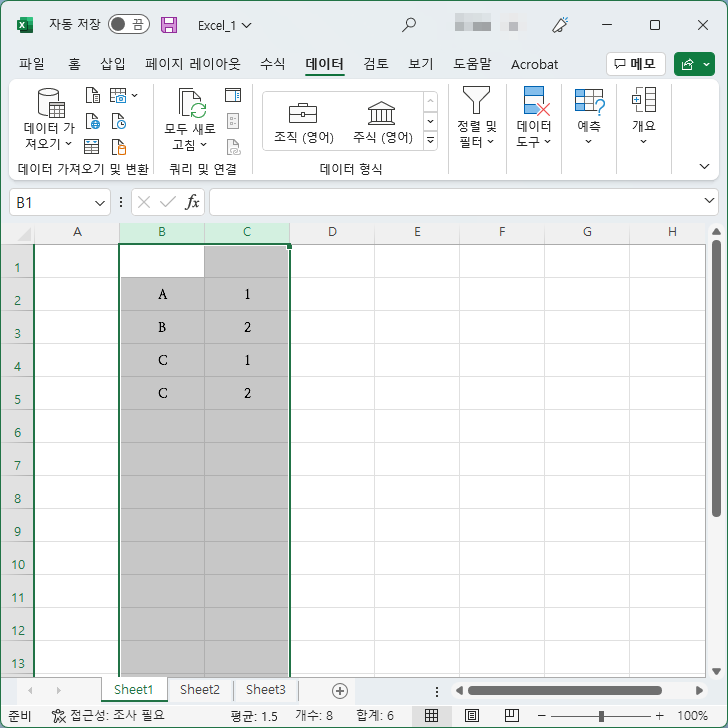
- 두 열에 모두 같은 값이 있는 행은 하나의 행만 남기고 사라집니다.
연말이 되면 여기저기서 달력을 받습니다. 고전적인 것도 있고 예쁜 것도 있습니다. 하지만 100% 마음에 드는 것은 없습니다. 그래서 엑셀로 나만의 달력을 만들었습니다. 달력을 만들 때 가장 귀찮은 것은 날짜를 채우는 것입니다. 날짜만 입력하면 나머지는 모양을 꾸미는 것이므로 어렵지 않습니다. 그렇다면 어떻게 날짜를 채울까요? 가로로 요일을 씁니다. 일요일 밑에 날짜를 입력합니다. 가로 방향으로 드래그하여 날짜를 ...
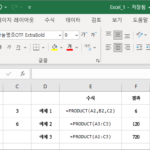
개요 PRODUCT는 곱을 구하는 함수이다. 곱은 *를 이용하여 구할 수도 있으나, 곱할 값들이 많으면 PRODUCT가 편하다. 구문 PRODUCT(number1, , ...) number1 : 필수 요소로, 곱하려는 첫 번째 숫자 또는 범위 number2, ... : 선택 요소로, 곱하려는 추가 숫자 또는 범위 최대 255개의 인수를 곱할 수 있다. 예제 예제 1 값을 지정하여 세 개의 값을 곱한다. 다음과 같은 결과를 얻는다. =A2*B2*C2 예제 2 범위를 ...
다른 셀의 값을 가져다 쓰는 걸 참조라고 한다. 참조의 대상이 되는 셀의 값이 바뀌면, 참조한 셀의 값도 바뀐다. 참조 방식은 상대 참조, 절대 참조, 혼합 참조 세 가지가 있다. 참조한 셀을 복사할 때의 결과가 가장 큰 차이이다. 상대 참조 예를 들어 셀 D3에서 셀 A1을 참조하면, 왼쪽으로 3칸, 위쪽의 2칸에 위치한 셀을 참조한다는 ...
엑셀 / 빈 셀, 빈 셀이 있는 행, 빈 셀이 있는 열 삭제하는 방법
빈 셀 또는 빈 셀을 포함한 행 또는 빈 셀을 포함한 열이 필요 없는 자료여서 삭제를 해야 할 때, 일일이 찾아서 삭제하는 것은 번거롭습니다. 자료가 많다면 시간도 많이 걸리고 실수할 가능성도 커집니다. 다행히 엑셀에는 그러한 작업을 쉽게 할 수 있는 기능을 포함하고 있습니다. 빈 셀 선택하기 빈 셀을 찾을 범위를 정합니다. 정하지 않아도 빈 ...
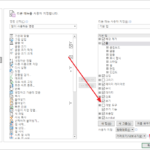
엑셀에서 VBA, 매크로 작업을 할 때 메뉴에 개발 도구가 있는 것이 편합니다. 그런데, 기본 설정은 개발 도구 메뉴를 보이지 않는 거라, 메뉴에 추가하기 위해서는 옵션을 수정해야 합니다. 상단 왼쪽의 을 클릭합니다. 왼쪽 아래에 있는 을 클릭합니다. 을 클릭합니다. 을 클릭합니다. 이제 메뉴에 개발 도구가 보입니다. 메뉴 구성은 다음과 같습니다.
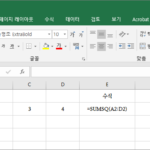
엑셀 / 함수 / SUMSQ / 제곱의 합 구하는 함수
개요 SUMSQ는 제곱의 합을 구하는 함수입니다. 구문 SUMSQ(number1, , ...) number1, number2, ... : number1은 필수 요소이고, 이후의 number는 선택 요소입니다. 인수는 255개까지 넣을 수 있습니다. 예제 1부터 4까지 제곱의 합을 구합니다.
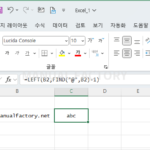
예를 들어 B2 셀에 있는 abc@manualfactory.net에서 @ 앞 부분을 추출하고 싶다면 다음과 같이 합니다. =LEFT(B2,FIND("@",B2)-1)
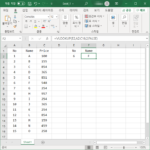
엑셀 / 함수 / VLOOKUP, HLOOKUP, XLOOKUP
VLOOKUP 문법 VLOOKUP(lookup_value,table_array,col_index_num,) lookup_value : 찾을 값 table_array : 조회할 범위 col_index_num : 반환하려는 값이 있는 열 번호 range_lookup : TRUE면 근사 일치, FALSE면 정확히 일치. 기본값은 TRUE 예제 =VLOOKUP(E2,A2:C16,2,FALSE) A2:C16의 1열(A열)에서 E2의 값을 찾고, 그 행의 2열(B열)의 값을 출력합니다. FALSE는 정확히 일치하는 것을 찾으라는 뜻입니다. E2에 6이 있으니, 6에 해당하는 이름 F를 출력합니다. =VLOOKUP(E2,A2:C16,3,FALSE) 가격을 출력하고 싶다면 2를 3으로 변경하면 됩니다. 선택 ...
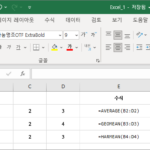
엑셀로 산술평균, 기하평균, 조화평균을 구할 수 있습니다. 사용하는 함수는 다음과 같습니다. 산술평균 : AVERAGE 기하평균 : GEOMEAN 조화평균 : HARMEAN 아래는 각각의 평균을 구하는 간단한 예제입니다. 아래는 위 예제에 대한 수식입니다.
엑셀 / 인쇄 / 바닥글에 총 페이지 수, 현재 페이지 번호 표시하는 방법
엑셀 워크시트를 인쇄할 때 페이지를 표시하는 게 좋습니다. 그래야 정리하기도 편하고, 찾기도 편합니다. 현재 페이지 번호만 인쇄를 하면 마지막 장을 잃어버려도 잃어버린지 모릅니다. 그런 문제를 해결하기 위해서는 전체 페이지 수도 같이 인쇄합니다. 현재 페이지 번호화 전체 페이지 수를 어떻게 바닥글에 넣고 인쇄하는지 알아보겠습니다. 페이지 설정 인쇄 화면에 있는 을 클릭합니다.(인쇄 미리보기 단축키는 Ctrl+P입니다.) 바닥글에서 ...