엑셀 / 나누기, 몫 구하기, 나머지 구하기
나누기
나누기는 슬래시 기호로 해요. 예를 들어 6 나누기 2는
6/2
와 같이 하면 됩니다.
몫 구하기
나누었을 때의 몫만 구하고 싶다면 QUOTIENT 함수를 이용하면 돼요.
QUOTIENT(numerator, denominator)
numerator에는 피제수, denominator에는 제수를 넣습니다.
나머지 구하기
나누었을 때의 나머지만 구하고 싶다면 MOD 함수를 사용합니다.
MOD(number, divisor)
number에는 피제수, divisor에는 제수를 입력합니다.
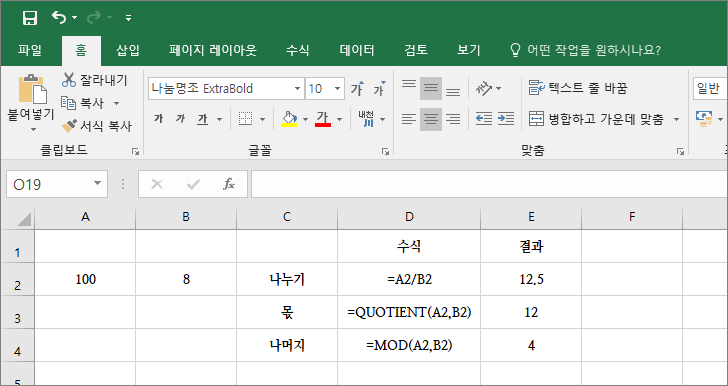
예제
다음은 100을 8로 나누어보고, 몫을 구하고, 나머지를 구하는 예제입니다.
보기 좋게 표를 만들거나 보고서를 만들려면 셀들을 합쳐야 할 때가 있습니다. 엑셀에서는 셀을 합치는 것을 병합이라고 하고, 다시 나누는 것을 분할이라고 합니다. 어떻게 병합하고 분할하는지, 병합에는 어떤 방법이 있는지 알아보겠습니다. 병합하고 가운데 맞춤 셀을 합치는 가장 간단한 방법은 합치려는 셀들을 선택하고 을 클릭하는 것입니다. 셀들이 하나도 합쳐지고, 텍스트는 가운데 정렬합니다. 셀 병합을 하면 ...
엑셀 / VBA / 매크로 단축키 만들기, 매크로 실행 버튼 만들기
매크로를 실행하는 기본적인 방법은 매크로 창을 열고, 매크로를 선택하고 실행 버튼을 클릭하는 것입니다. 만약 자주 사용하는 매크로가 있다면 단축키를 만들거나 매크로 실행 버튼을 눌러 시간을 단축할 수 있습니다. 매크로 단축키 만들기 를 클릭합니다. 단축키는 Alt+F8입니다. 매크로를 선택하고 을 클릭합니다. 단축키를 지정하고 을 클릭하면, 그 단축키로 매크로를 실행할 수 있습니다. 매크로 실행 버튼 만들기 ...
엑셀에 기호 또는 특수 문자를 입력하는 방법은 두 가지가 있습니다. 삽입 - 메뉴 상단에서 를 클릭합니다. 글꼴을 바꾸가면서 필요한 기호를 찾습니다. 기호를 선택한 후 을 클릭하면 기호가 셀에 삽입됩니다. 자음 + 한자 ㄱ, ㄴ 등 자음을 입력하고 한자 키를 누릅니다. 그러면 특수 문자가 나옵니다. 화살표를 클릭하면 입력할 수 있는 기호를 ...
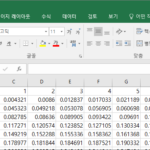
엑셀 / 로그 또는 상용로그의 값 구하기, 상용로그표 만들기
로그 또는 상용로그의 값 구하기 로그의 값을 구하는 함수는 LOG에요. 외우기 쉽게 이름을 만들었네요. LOG(number, ) number에는 진수, base에는 밑이 들어가요. 즉 LOG(8, 2) 는 log28을 뜻합니다. 만약 base가 생략되었다면 밑을 10으로 계산해요. 밑이 10인 로그를 상용로그라고 하는 거 기억하시죠? 상용로그의 값은 함수 LOG10을 사용해도 돼요. LOG10(number) 따라서 상용로그의 값을 구하는 방법은 세가지가 있습니다. LOG(100, 10) LOG(100) LOG10(100) 상용로그표 만들기 상용로그표를 만들어볼게요. 고등학교 때 수학 ...
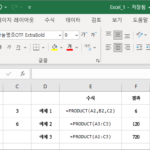
개요 PRODUCT는 곱을 구하는 함수이다. 곱은 *를 이용하여 구할 수도 있으나, 곱할 값들이 많으면 PRODUCT가 편하다. 구문 PRODUCT(number1, , ...) number1 : 필수 요소로, 곱하려는 첫 번째 숫자 또는 범위 number2, ... : 선택 요소로, 곱하려는 추가 숫자 또는 범위 최대 255개의 인수를 곱할 수 있다. 예제 예제 1 값을 지정하여 세 개의 값을 곱한다. 다음과 같은 결과를 얻는다. =A2*B2*C2 예제 2 범위를 ...
틀 고정 엑셀에 데이터를 입력할 때 보통 표 형태로 넣습니다. 첫 행에 제목을 넣고 밑으로 주욱 입력하거나, 첫 열에 제목을 넣고 오른쪽으로 주욱 입력을 하죠. 자료가 많다면 입력한 내용이 한 화면에 다 나오지 않습니다. 그 보이지 않는 부분을 볼려면 아래로 또는 오른쪽으로 스크롤해야 하는데, 그럴 경우 제목 행 또는 제목 열이 안보여서 ...
엑셀에서 슬래시(/)를 입력하려고 하면 입력이 되는 대신 Alt 키를 누른 것과 같은 결과를 냅니다. 슬래시를 입력하는 방법 세가지를 소개합니다.
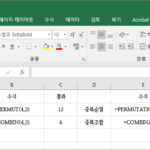
엑셀 / 순열의 수, 중복순열의 수, 조합의 수, 중복조합의 수 계산하기
경우의 수 구하는 함수 엑셀로 순열의 수, 중복순열의 수, 조합의 수, 중복조합의 수를 계산할 수 있습니다. 순열의 수는 PERMUT 함수로, 중복순열의 수는 PERMUTATIONA 함수로, 조합의 수는 COMBIN 함수로, 중복조합의 수는 COMBINA 함수로 구합니다. 구문 PERMUT(number, number_chosen) PERMUTATIONA(number, number_chosen) COMBIN(number, number_chosen) COMBIN(number, number_chosen) number : 필수 요소로, 항목 수입니다. number_chosen : 필수 요소로, 각 경우의 수에 포함되는 항목 수입니다. 순열의 수, 중복순열의 ...
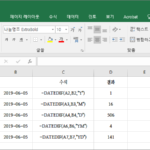
엑셀 / 함수 / DATEDIF / 두 날짜 사이의 일수, 월수, 년수 등을 계산하는 함수
개요 DATEDIF는 두 날짜 사이의 일수, 월수, 년수 등을 계산하는 함수입니다. 구문 DATEDIF(start_date,end_date,unit) start_date : 시작하는 날짜입니다. end_date : 끝나는 날짜입니다. unit : 반환할 정보의 형식입니다. Y, M, D, YM, YD 등을 사용할 수 있습니다. Y는 년수, M은 월수, D는 일수, YM은 년도를 무시한 월수, YD는 년도를 무시한 일수를 반환합니다. start_date가 end_date보다 이후라면 #NUM!를 반환합니다. 예제 다음은 2018년 1월 15일부터 2019년 6월 5일까지의 ...
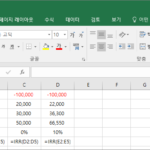
개요 IRR 함수는 주기적인 현금 흐름에 대한 내부수익률(internal rate of return)을 반환하는 함수입니다. 구문 IRR(values, ) values 필수 요소로, 셀에 대한 참조 또는 배열입니다. 양수 값과 음수 값이 각각 한 개 이상씩 포함되어야 합니다. 텍스트, 논리값 또는 빈 셀은 무시됩니다. guess 선택 요소로, IRR 계산에 처음 사용할 값입니다. guess에서 시작하여 결과가 0.00001% 이내의 오차 범위에 들어올 때까지 반복합니다. guess를 생략하면 0.1(10%)로 간주합니다. 20번 이상 반복한 후에도 ...