엑셀 / 함수 / LEFT, LEFTB, MID, MIDB, RIGHT, RIGHTB / 문자열 추출 함수
LEFT, LEFTB
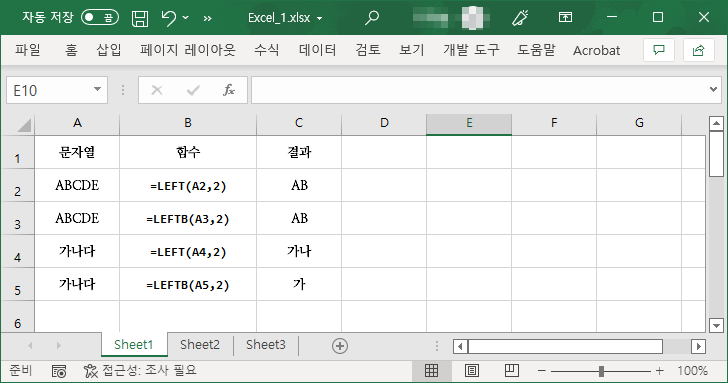
LEFT는 텍스트 문자열의 첫 번째 문자부터 시작하여 지정한 문자 수만큼 문자를 반환한다.
LEFT(text, [num_chars])
LEFTB는 텍스트 문자열의 첫 번째 문자부터 시작하여 지정한 바이트 수만큼 문자를 반환한다.
LEFTB(text, [num_bytes])
영문자 등은 한 문자가 1바이트이므로 결과에 차이가 없다. 하지만, 한글 등 2바이트 문자라면 차이가 난다.
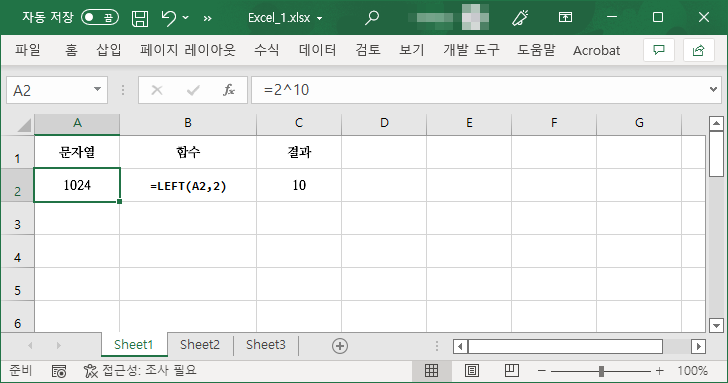
수식으로 계산된 결과에 대해서도 적용할 수 있다.
MID, MIDB
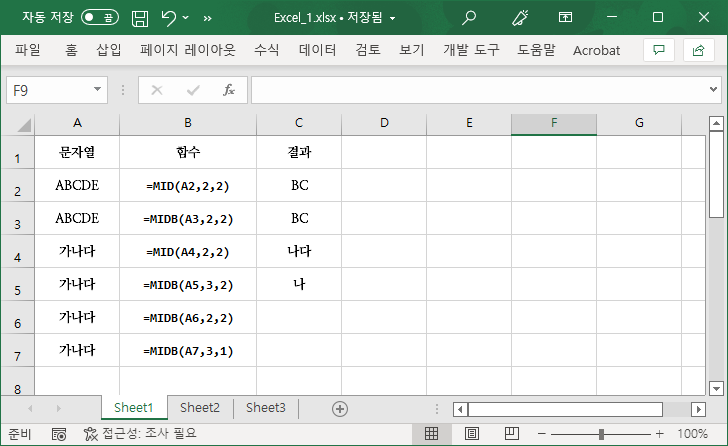
MID는 텍스트 문자열에서 지정된 위치로부터 지정된 수만큼 문자를 반환한다.
MID(text, start_num, num_chars)
MIDB는 지정한 바이트 수에 따라 문자열의 지정한 위치로부터 지정한 개수의 문자를 반환한다.
MIDB(text, start_num, num_bytes)
영문자 등은 한 문자가 1바이트이므로 결과에 차이가 없다. 하지만, 한글 등 2바이트 문자라면 차이가 난다.
한글 등의 경우 시작 위치나 추출할 문자 수에 따라 MIDB의 결과가 출력되지 않을 수 있다.
RIGHT, RIGHTB
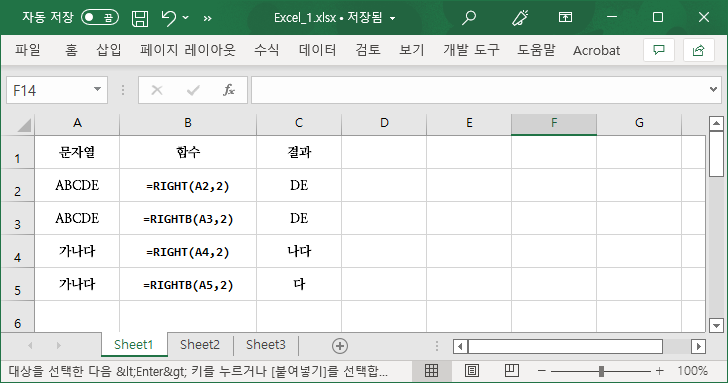
RIGHT는 텍스트 문자열의 마지막 문자부터 시작하여 지정한 문자 수만큼 문자를 반환한다.
RIGHT(text, [num_chars])
RIGHTB는 텍스트 문자열의 마지막 문자부터 시작하여 지정한 바이트 수만큼 문자를 반환한다.
RIGHTB(text, [num_bytes])
영문자 등은 한 문자가 1바이트이므로 결과에 차이가 없다. 하지만, 한글 등 2바이트 문자라면 차이가 난다.
엑셀 / 오름차순 정렬하기, 내림차순 정렬하기, 여러 기준으로 정렬하기
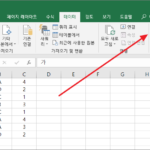
엑셀에서 정렬은 데이터 탭에서 한다. 한 개를 기준으로 정렬할 수도 있고, 여러 개를 기준으로 정렬할 수도 있다. 한 개를 기준으로 정렬하기 정렬하려는 값들이 있는 셀 중에서 정렬 기준이 될 열에 있는 셀 중 하나를 선택한다. 을 클릭하면 내림차순으로 정렬한다. 정렬할 영역은 엑셀이 자동으로 정한다. 여러 개를 기준으로 정렬하기 버튼을 클릭하면 ...
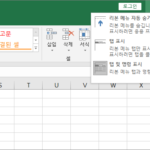
탭과 리본 메뉴 엑셀을 실행시키면 상단에 여러 메뉴들이 있습니다. 제일 위에 있는 파일, 홈, 삽입 등을 탭이라 하고, 탭 밑에 있는 것을 리본 메뉴라고 합니다. 아래 스크린샷에서 빨간 박스 부분이 리본 메뉴입니다. 리본 메뉴가 상당히 두꺼워서 노트북 같이 화면이 작은 기기에서 작업할 때 불편할 수 있습니다. 그럴 땐 필요할 때만 리본 메뉴가 ...
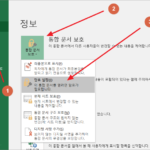
암호 종류 엑셀에는 두 가지 암호가 있어요. 하나는 열기 암호, 또 하나는 쓰기 암호입니다. 둘 중 하나만 설정해도 되고, 둘 다 설정해도 돼요. 열기 암호를 설정하면 문서를 열 때 암호가 필요합니다. 암호를 모르면 문서 내용을 볼 수 없어요. 쓰기 암호를 설정하면 문서를 수정할 때 암호가 필요합니다. 암호를 몰라도 문서의 내용은 볼 수 있어요. 열기 암호와 ...
엑셀 / 함수 / XIRR / 비정기적인 현금 흐름의 내부수익률 계산하는 함수
개요 XIRR 함수는 비정기적인 현금 흐름의 내부수익률(internal rate of return)을 반환하는 함수입니다. 구문 XIRR(values, dates, ) values 필수 요소로, dates의 지불 일정에 대응하는 현금 흐름입니다. 양수 값과 음수 값이 각각 한 개 이상씩 포함되어야 합니다. dates 필수 요소로, values에 대응하는 지불 일정입니다. guess 선택 요소로, XIRR 계산에 처음 사용할 값입니다. guess에서 시작하여 결과의 오차가 0.000001% 이내로 정확해질 때까지 반복합니다. guess를 생략하면 0.1(10%)로 간주합니다. 100번 ...
엑셀 / 화살표 키 눌렀을 때 스크롤 되는 현상 해결하는 방법
보통 셀이 선택된 상태에서 화살표 키를 누르면 선택된 셀이 이동한다. 예를 들어 A1이 선택된 상태에서 오른쪽 화살표 키를 누르면 B1이 선택된다. 그런데, 선택된 셀이 이동하는 게 아니라 시트 자체가 스크롤 되는 경우가 있다. 그렇게 되는 이유는 자신도 모르게 Scroll Lock를 눌렀기 때문... 다시 Scroll Lock을 누르면 원래대로 돌아온다.
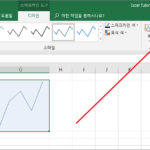
스파크라인 스파크라인은 데이터를 시각적으로 나타내줍니다. 챠트와 비슷해서 미니 챠트라고 부르기도 합니다. 챠트와 스파크라인의 차이점 중의 하나는, 스파크라인은 셀에 속한다는 것입니다. 그리고 셀의 값이 아니라 배경으로 만들어집니다. 스파크라인 만들기 이 있습니다. 적절한 모양을 정하고 클릭합니다.(모양은 나중에 바꿀 수 있습니다.) 라는 창이 뜹니다. 범위를 선택하고 을 클릭하면 스파크라인이 만들어집니다. 스파크라인 모양 바꾸기 스파크라인을 선택하면 디자인 탭이 ...
엑셀에서 Rkakrnl를 입력하면 까마귀로 바뀝니다. 한글로 입력해야 할 것을 실수로 영어로 입력했을 거라 판단하여 한글로 변경해주는 기능입니다. 만약 이 기능이 불편하다면 옵션에서 비활성화할 수 있습니다.
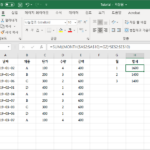
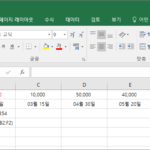
다음과 같이 날짜별 제품 판매 데이터가 있습니다. 이 자료를 가지고 월별 판매액 합계를 구하는 방법 두 가지를 소개해드립니다. 방법 1 MONTH 함수로 날짜에서 월을 뽑아냅니다. SUMIF 함수로 월별 금액의 합계를 구합니다. 의미 없는 F열을 추가해야 한다는 단점이 있습니다. 방법 2 날짜에서 월을 뽑아, 해당 월의 금액 합계를 구합니다. =SUM((MONTH($A$2:$A$10)=G2)*$E$2:$E$10) 수식이 약간 복잡해지지만, 월별 합계를 구하기 위한 열을 추가할 ...
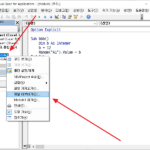
엑셀에서 VBA로 만든 모듈을 다른 파일에서 사용하는 방법은, 그 모듈을 내보내고 다른 파일에서 가져오는 것입니다. 작업은 Visual Basic Editor에서 합니다. 모듈 내보내기 내보내기를 할 엑셀 파일을 열고 Visual Basic Editor를 엽니다. 단축키는 Alt+F11입니다. 내보낼 모듈을 선택하고 마우스 우클릭합니다. 팝업 메뉴에서 를 클릭하면 확장자가 bas인 파일로 저장됩니다. bas 파일은 텍스트 파일로, 메모장 등 텍스트 에디터로 ...
눈금선 엑셀의 시트에는 선이 있어요. 모니터에만 나오고 인쇄할 때는 나오지 않는 선이에요. 이 선을 눈금선이라고 합니다. 눈금선이 있는 이유는 셀의 위치를 파악하기 쉽게 하려는 거에요. 눈금선 없이 한동안 써봤는데 꽤 불편하더군요. 눈금선이 있는 게 좋아요. 그런데, 눈금선이 있는 게 더 불편한 경우가 있어요. 바로 모양을 꾸밀 때에요. 인쇄용 보고서를 만들기 위해 선을 그리고 ...