엑셀 / 랜덤 정렬하는 방법
엑셀은 셀의 값, 셀의 색, 글자 색 등을 기준으로 정렬할 수 있습니다. 보통은 특정 기준으로 차례대로 정렬하는 것이 보기 좋습니다.
하지만 간혹 랜덤하게 나열해야하는 경우도 있습니다. 예를 들어 영어 단어 시험지를 만들 때, 순서 다른 여러 가지를 만들면 부정 행위의 위험을 줄일 수 있겠죠.
안타깝게도 엑셀에는 랜덤 정렬이라는 게 없어서 편법을 사용해야 합니다.
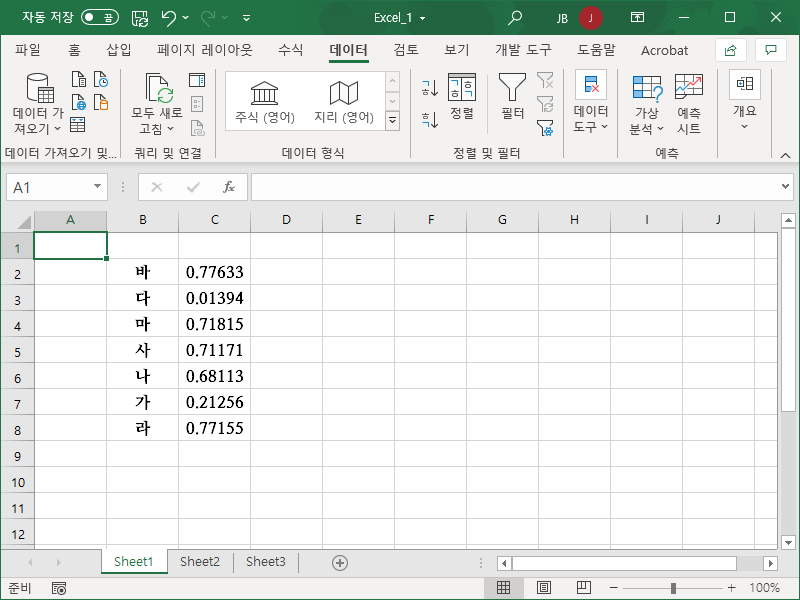
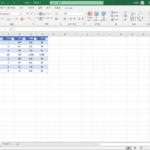
- 랜덤하게 순서를 바꾸고 싶은 데이터가 아래와 같이 있다고 합시다.
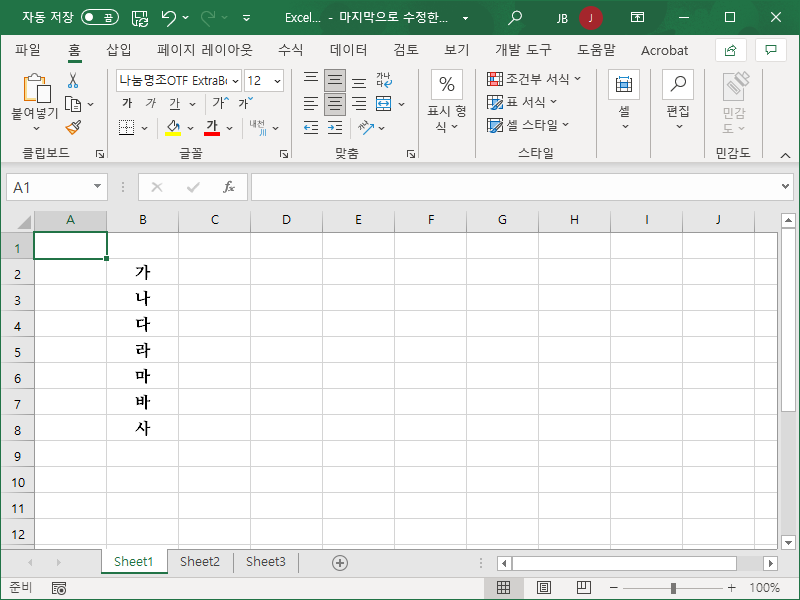
- 그 옆에 RAND 함수로 난수를 만듭니다.
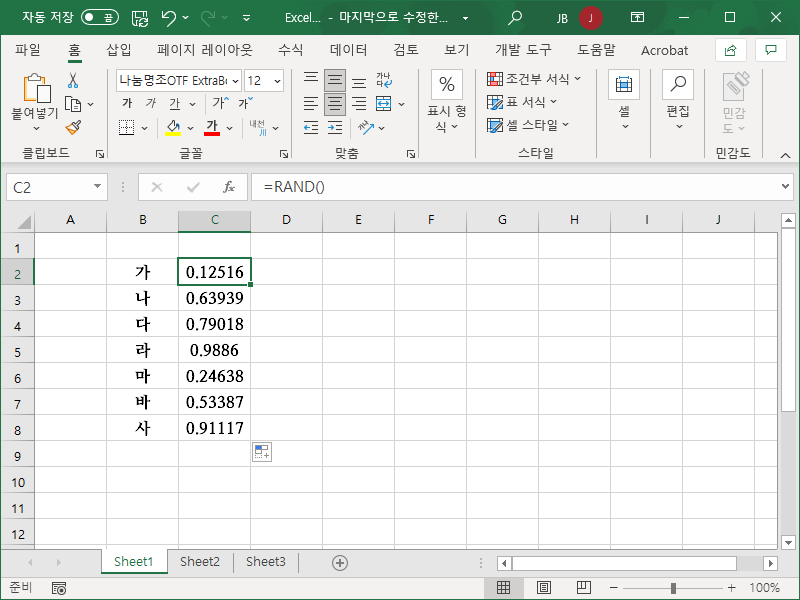
- 그리고 두 열을 함께 정렬을 하는데...
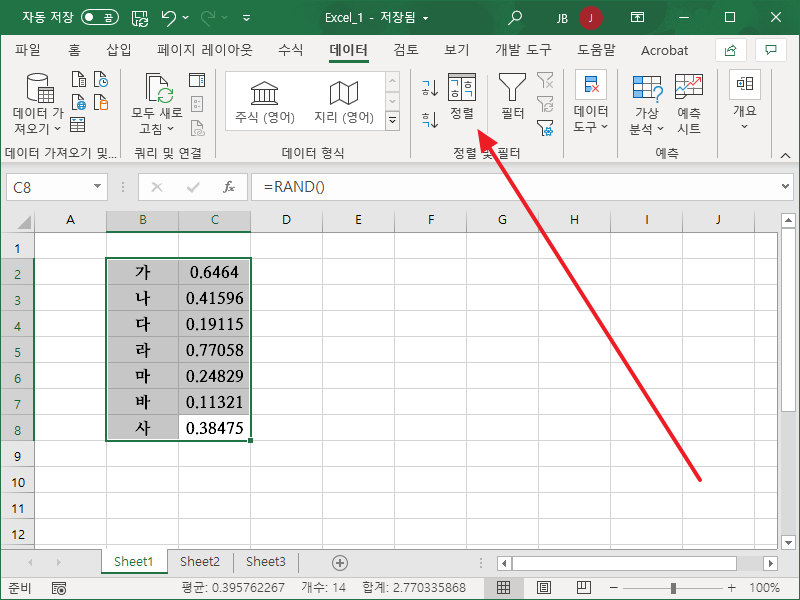
- 기준을 난수의 오름차순으로 정합니다.
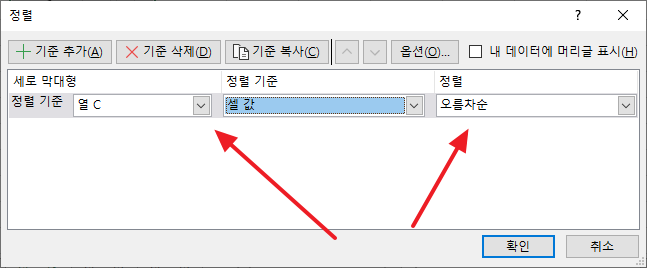
- 그러면 아래처럼 랜덤 정렬이 완성됩니다.
- 이제 C열은 필요 없으니 지워도 됩니다.
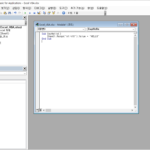
간단한 예제로, VBA로 매크로를 만들고 실행하는 과정을 살펴보겠습니다.(개발 도구 메뉴가 없는 경우 옵션 변경으로 추가할 수 있습니다.) 을 클릭합니다.(단축키는 Alt+F11입니다.) 다음과 같은 에디터 창이 나오는데... 을 클릭합니다. 코드를 넣을 수 있는 창이 나오는데... 다음 코드를 입력합니다. Sub SayHello() Sheet1.Range("A1").Value = "HELLO" End ...
틀 고정 엑셀에 데이터를 입력할 때 보통 표 형태로 넣습니다. 첫 행에 제목을 넣고 밑으로 주욱 입력하거나, 첫 열에 제목을 넣고 오른쪽으로 주욱 입력을 하죠. 자료가 많다면 입력한 내용이 한 화면에 다 나오지 않습니다. 그 보이지 않는 부분을 볼려면 아래로 또는 오른쪽으로 스크롤해야 하는데, 그럴 경우 제목 행 또는 제목 열이 안보여서 ...

함수 이름 유형 설명 ABS 수학 및 삼각법 숫자의 절댓값 반환 ACCRINT 재무 정기적으로 이자를 지급하는 유가 증권의 경과 이자를 반환 ACCRINTM 재무 만기에 이자를 지급하는 유가 증권의 경과 이자를 반환 ACOS 수학 및 삼각법 숫자의 아크코사인을 반환 ACOSH 수학 및 삼각법 숫자의 역 하이퍼볼릭 코사인을 반환 ACOT 수학 및 삼각법 아크코탄젠트 값을 반환 ACOTH 수학 및 삼각법 하이퍼볼릭 아크코탄젠트 값을 반환 AGGREGATE 수학 및 삼각법 목록 또는 데이터베이스에서 집계 값을 반환 ADDRESS 조회 및 참조 행과 열 번호를 ...
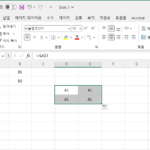
다른 셀의 값을 가져다 쓰는 걸 참조라고 한다. 참조의 대상이 되는 셀의 값이 바뀌면, 참조한 셀의 값도 바뀐다. 참조 방식은 상대 참조, 절대 참조, 혼합 참조 세 가지가 있다. 참조한 셀을 복사할 때의 결과가 가장 큰 차이이다. 상대 참조 예를 들어 셀 D3에서 셀 A1을 참조하면, 왼쪽으로 3칸, 위쪽의 2칸에 위치한 셀을 참조한다는 ...
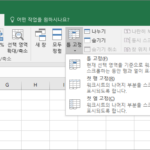
엑셀에서 VBA로 만든 모듈을 다른 파일에서 사용하는 방법은, 그 모듈을 내보내고 다른 파일에서 가져오는 것입니다. 작업은 Visual Basic Editor에서 합니다. 모듈 내보내기 내보내기를 할 엑셀 파일을 열고 Visual Basic Editor를 엽니다. 단축키는 Alt+F11입니다. 내보낼 모듈을 선택하고 마우스 우클릭합니다. 팝업 메뉴에서 를 클릭하면 확장자가 bas인 파일로 저장됩니다. bas 파일은 텍스트 파일로, 메모장 등 텍스트 에디터로 ...
엑셀 / 중복된 값 찾는 방법, 중복 항목 제거하는 방법
엑셀로 자료를 취합하고 정리하다보면 중복된 값들이 생기기도 합니다. 그런 중복 항목을 찾기 위해 눈으로 검토할 필요는 없습니다. 엑셀에는 중복된 항목을 찾거나, 찾아서 제거하는 기능이 있기 때문입니다. 중복 값 찾기 중복 값을 찾을 열을 선택합니다. 을 클릭합니다. 을 클릭하면... 중복된 값이 강조됩니다. 조건부 서식에서 를 ...
엑셀 / 함수 / UPPER, LOWER, PROPER / 대문자로 또는 소문자로 변환하는 함수
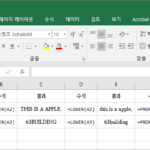
개요 UPPER, LOWER, PROPER는 대문자 또는 소문자 변환과 관련된 함수입니다. UPPER : 모두 대문자(upper case)로 바꿉니다. LOWER : 모두 소문자(lower case)로 바꿉니다. PROPER : 단어의 첫글자는 대문자로, 나머지는 소문자로 바꿉니다. 구문 UPPER(text) LOWER(text) PROPER(text) text : 필수 요소로, 대문자로 또는 소문자로 변환할 텍스트입니다. PROPER 함수 단어의 첫째 문자를 대문자로 변환하고, 나머지 문자들은 소문자로 변환합니다. 예를 들어 PROPER("abCdE") 는 Abcde입니다. 단어의 첫째 문자가 영문자가 아닌 경우, 영문자가 아닌 문자 다음에 오는 영문자를 대문자로 ...
엑셀은 PDF 저장 기능을 갖고 있습니다. Acrobat 등 PDF 변환 프로그램을 설치하지 않아도 PDF 형식의 문서로 변환할 수 있습니다. PDF로 저장하는 방법은 두 가지가 있는데, 하나는 을 이용하는 게 더 편합니다. F12를 눌러서 창을 엽니다. 파일 형식을 PDF로 ...
피벗 테이블을 만들었을 때, 데이터 표시 방법이 마음에 들지 않을 수 있습니다. 접고 펴기가 가능한 그룹화된 모양인데, 경우에 따라서 일반적인 표 모양의 결과물이 필요할 수도 있죠. 만약 표시 형식을 바꾸고 싶다면 피벗 테이블의 레이아웃을 변경하면 됩니다. 아래와 같은 표로 여러 가지 레이아웃의 피벗 테이블을 만들어보겠습니다. 워크시트를 하나 추가하고, 을 클릭합니다. [외부 ...
눈금선 엑셀의 시트에는 선이 있어요. 모니터에만 나오고 인쇄할 때는 나오지 않는 선이에요. 이 선을 눈금선이라고 합니다. 눈금선이 있는 이유는 셀의 위치를 파악하기 쉽게 하려는 거에요. 눈금선 없이 한동안 써봤는데 꽤 불편하더군요. 눈금선이 있는 게 좋아요. 그런데, 눈금선이 있는 게 더 불편한 경우가 있어요. 바로 모양을 꾸밀 때에요. 인쇄용 보고서를 만들기 위해 선을 그리고 ...