엑셀 / 숫자를 한글 또는 한자로 나타내는 방법
수를 한글로 표시해야할 때가 간혹 있습니다. 한글로 쓰면 위변조가 어려워서 그렇다고 알고 있는데, 진짜 이유가 그것인지는 잘 모르겠습니다.
수를 한글로 나타내기 위해서 처음부터 한글로 입력할 필요는 없습니다. 엑셀에는 수를 한글로 나타내는 기능이 있기 때문입니다. 이 기능을 이용해야 엑셀에서 숫자로 취급합니다.
수를 입력한 후 마우스 우클릭해서 [셀 서식]을 엽니다.
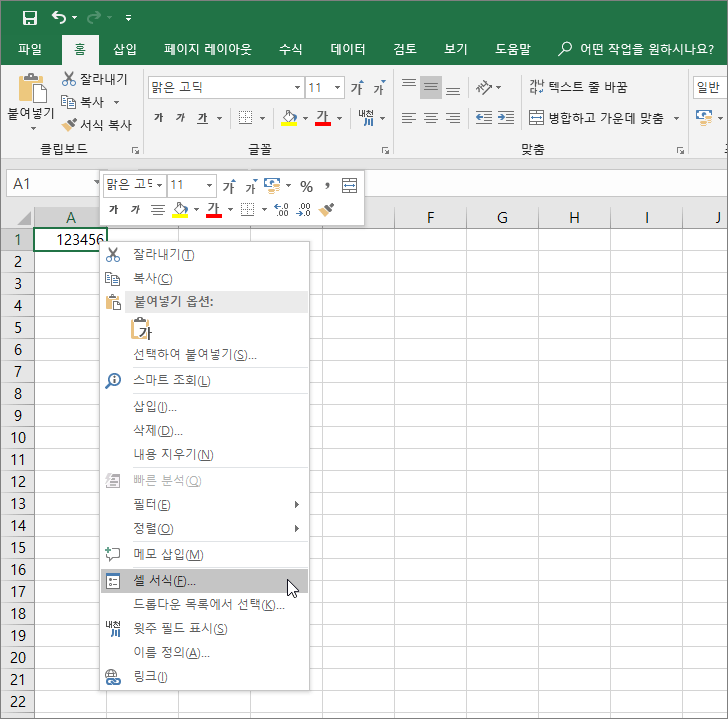
범주에서 [기타]를 선택한 후 형식에서 [숫자(한글)]를 선택합니다. 보기에서 어떻게 표시되는지 확인할 수 있습니다. 123456을 일십이만삼천사백오십육으로 나타내는군요.
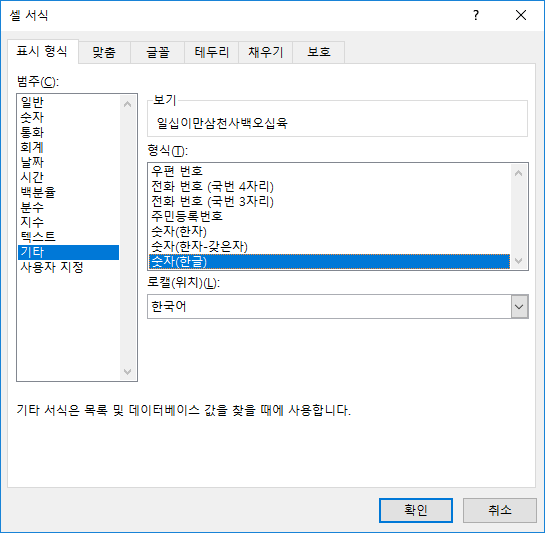
한자로 나타낼 수도 있습니다. 형식에서 [숫자(한자)]를 선택하면 됩니다.
개요 ABS 함수는 'absolute value'의 약자로, 숫자의 절댓값을 구하는 함수입니다. 절댓값은 숫자의 크기만을 나타내며, 부호를 무시합니다. 예를 들어, -5의 절댓값은 5이고, 5의 절댓값은 그대로 5입니다. 구문 ABS(number) number: 절댓값을 구하고자 하는 숫자입니다. 이 인수는 숫자 자체일 수도 있고 셀 참조나 수식의 결과일 수도 있습니다. 예제 기본 예제 절댓값을 구하고자 하는 숫자를 직접 함수에 입력하는 방법입니다. 다음은 25를 반환합니다. =ABS(-25) 다음은 ...
엑셀 / 함수 / INT, TRUNC / 소수를 정수 만드는 함수
개요 소수를 정수로 만드는 함수에는 INT 함수와 TRUNC 함수가 있습니다. 정수로 만든다는 점은 같지만, 정수로 만드는 방식에는 차이가 있으므로 사용에 주의를 해야 합니다. 차이점 1 INT 함수는 작거나 같은 정수로 만듭니다. 예를 들어 INT(2.6) 은 2.6보다 작은 정수인 2가 되고, INT(-2.6) 은 -2.6보다 작은 정수인 -3이 됩니다. TRUNC 함수는 소수점 아래의 수를 지워버립니다. 예를 들어 TRUNC(2.6) 은 소수점 아래의 수 6을 ...
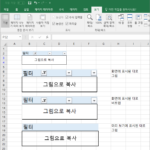
엑셀로 작업한 결과 또는 시트의 일부분을 그림으로 만들어야 하는 경우가 간혹 있습니다. 어떻게 이미지로 만들 수 있을까요? 가장 먼저 떠오르는 건 픽픽 같은 캡쳐 프로그램으로 캡쳐를 하는 것입니다. 문제는 별도의 프로그램을 설치해야 한다는 것이죠. 또 다른 방법은, 사실 가장 간편한 방법은 엑셀에 포함된 기능을 이용하는 것입니다. 따로 프로그램이 필요한 것도 ...
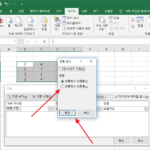
엑셀에서 정렬할 때 대부분 세로 방향으로 정렬합니다. 데이터를 세로 방향으로 정리하는 경우가 많기 때문입니다. 엑셀의 기본 정렬 방향도 위에서 아래로 향하는 세로 방향입니다. 그런데 항상 그런 건 아닙니다. 경우에 따라서 데이터를 가로 방향으로 정리하기도 있습니다. 그렇다면 정렬을 할 때에도 가로 방향으로 해야겠죠? 어떻게 해야 가로 방향 정렬을 할 수 있을까요? 해결책은 옵션에 ...
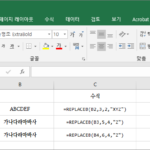
엑셀 / 함수 / REPLACE, REPLACEB / 특정 위치의 문자열을 바꾸는 함수
개요 REPLACE와 REPLACEB는 특정 위치의 문자열을 다른 문자열로 바꾸는 함수입니다. 특정 위치를 찾을 때 REPLACE 함수는 글자 수를 기준으로 하고, REPLACEB 함수는 바이트를 기준으로 합니다. 따라서 한 글자를 2바이트로 계산하는 한국어, 일본어, 중국어에서 차이가 납니다. 구문 REPLACE REPLACE(old_text, start_num, num_chars, new_text) old_text : 필수 요소로, 문자를 바꿀 문자열입니다. start_num : 필수 요소로, old_text에서 new_text로 바꿀 문자의 위치입니다. num_chars : 필수 요소로, old_text에서 사라질 문자의 ...
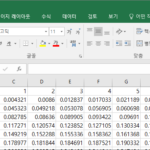
엑셀 / 로그 또는 상용로그의 값 구하기, 상용로그표 만들기
로그 또는 상용로그의 값 구하기 로그의 값을 구하는 함수는 LOG에요. 외우기 쉽게 이름을 만들었네요. LOG(number, ) number에는 진수, base에는 밑이 들어가요. 즉 LOG(8, 2) 는 log28을 뜻합니다. 만약 base가 생략되었다면 밑을 10으로 계산해요. 밑이 10인 로그를 상용로그라고 하는 거 기억하시죠? 상용로그의 값은 함수 LOG10을 사용해도 돼요. LOG10(number) 따라서 상용로그의 값을 구하는 방법은 세가지가 있습니다. LOG(100, 10) LOG(100) LOG10(100) 상용로그표 만들기 상용로그표를 만들어볼게요. 고등학교 때 수학 ...
엑셀 / 함수 / IFERROR / 에러 메시지를 변경하는 함수
개요 엑셀에서 함수 사용 시 문제가 발생하면 에러 메시지가 나옵니다. 꼭 수정해야 하는 에러도 있지만, 어쩔 수 없이 생기는 에러도 있습니다. 만약 후자라면 IFERROR 함수로 에러 메시지를 다른 것으로 대체할 수 있습니다. 구문 IFERROR(value, value_if_error) value : 필수 요소입니다. 오류를 검사할 인수입니다. value_if_error : 필수 요소입니다. 수식이 오류로 평가되는 경우 반환할 값입니다. 예제 예를 들어 어떤 수를 ...
화면 확대/축소 엑셀의 기본 글자 크기는 보통 11pt입니다. 대부분 그 크기에 익숙해져있지만, 좀 더 크게 또는 좀 더 작게 보는 게 편할 때가 있습니다. 글자 크기를 변경하는 방법도 있지만, 다른 사람과 자료를 공유해야 하거나, 프린터로 인쇄해야 하는 경우에는, 글자 크기는 그대로 둔 채 화면만 확대/축소하는 게 좋습니다. 화면을 확대/축소하는 방법 두 가지를 소개해드립니다. 방법 ...
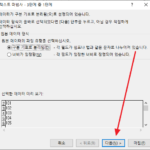
숫자이기는 하지만 데이터 형식이 숫자가 아니라 문자(텍스트)여야 하는 경우가 있다. 이미 숫자로 입력된 상태에서 텍스트로 형식을 변경하는 방법 세 가지를 소개한다. 대부분 방법 1로 해결이 되나, 문제가 있다면 방법 3을 사용한다. 방법 1 - 표시 형식 변경 다음과 같은 숫자 데이터가 있다면... 셀을 선택한 후 마우스 우클릭하고 을 클릭합니다. 표시 형식을 을 ...
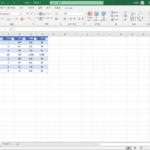
피벗 테이블을 만들었을 때, 데이터 표시 방법이 마음에 들지 않을 수 있습니다. 접고 펴기가 가능한 그룹화된 모양인데, 경우에 따라서 일반적인 표 모양의 결과물이 필요할 수도 있죠. 만약 표시 형식을 바꾸고 싶다면 피벗 테이블의 레이아웃을 변경하면 됩니다. 아래와 같은 표로 여러 가지 레이아웃의 피벗 테이블을 만들어보겠습니다. 워크시트를 하나 추가하고, 을 클릭합니다. [외부 ...