엑셀 / 행의 최대 개수, 열의 최대 개수, 셀의 최대 개수
행, 열, 셀
엑셀은 표 형태로 되어 있어요. 가로를 행이라 하고, 세로를 열이라 하고, 각 칸을 셀이라 합니다.
행은 숫자로 구분하고, 열은 문자로 구분해요. 셀은 열과 행의 이름을 합하여 나타냅니다. 예를 들어 D3는 D열과 3행이 만나는 셀을 의미합니다.
사용할 수 있는 행과 열의 개수는 정해져있어요. 꽤 많긴 하지만 무한대로 있지는 않아요. 최대 몇 개를 사용할 수 있는지 알아보겠습니다.
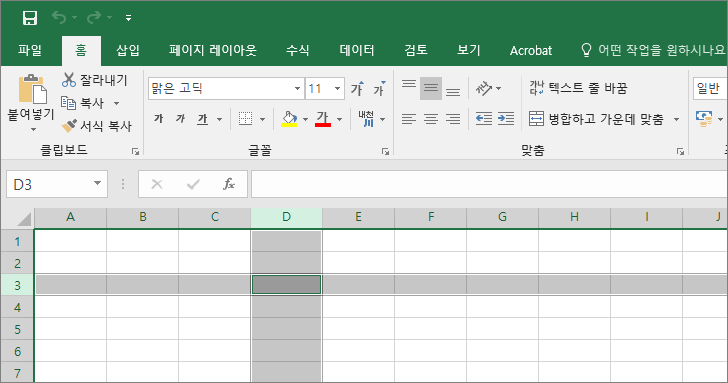
행의 최대 개수
Ctrl 키를 누른 상태에서 아래쪽 화살표 키를 누르면 제일 밑의 행으로 이동합니다. 1048576개가 행의 최대 개수입니다.
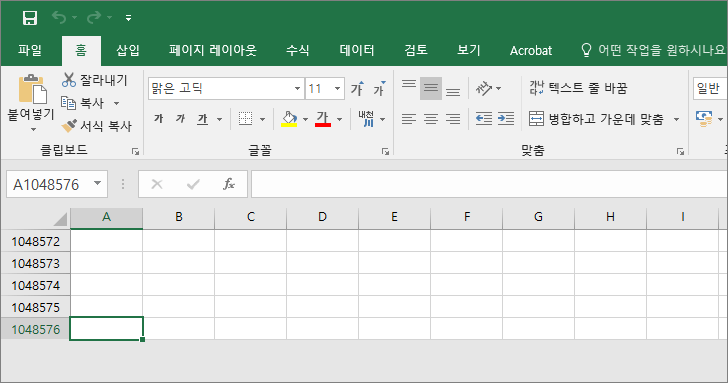
열의 최대 개수
Ctrl 키를 누른 상태에서 오른쪽 화살표 키를 누르면 제일 오른쪽의 열로 이동합니다. XFD열이 마지막입니다.
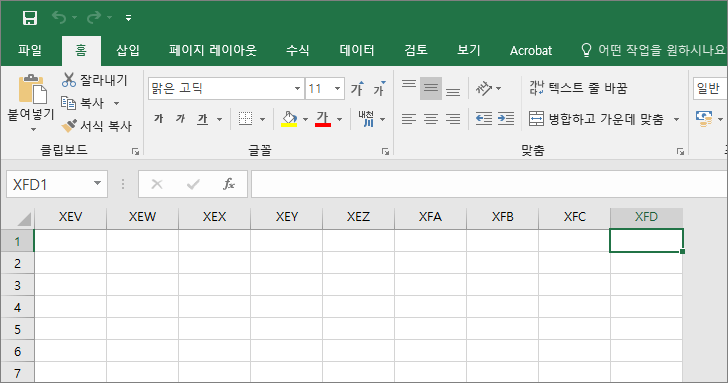
A-Z가 26개, AA-ZZ가 676개, AAA-WZZ가 15548개, XAA-XEZ가 130개, XFA-XFD가 4개이므로, 열의 최대 개수는 16384개입니다.
셀의 최대 개수
셀의 최대 개수는 행의 최대 개수와 열의 최대 개수를 곱하여 구합니다.
1048576×16384=17179869184
이 셀들을 다 사용할 날이 올까 모르겠네요.
엑셀 / 함수 / COUNT, COUNTA, COUNTBLANK, COUNTIF, COUNTIFS
개요 셀 개수를 세는 함수에는 COUNT, COUNTA, COUNTBLANK, COUNTIF, COUNTIFS가 있다. COUNT는 숫자가 있는 셀의 개수, COUNTA는 비어 있지 않은 셀의 개수, COUNTBLANK는 비어 있는 셀의 개수, COUNTIF는 조건에 맞는 셀의 개수, COUNTIFS는 여러 조건에 맞는 셀의 개수를 반환한다. 구문 COUNT COUNT(value1, , ...) 숫자가 있는 셀의 개수를 반환한다. 비어 있거나 문자가 있는 셀은 세지 않는다. COUNTA COUNTA(value1, , ...
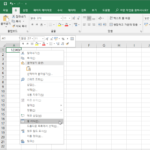
수를 한글로 표시해야할 때가 간혹 있습니다. 한글로 쓰면 위변조가 어려워서 그렇다고 알고 있는데, 진짜 이유가 그것인지는 잘 모르겠습니다. 수를 한글로 나타내기 위해서 처음부터 한글로 입력할 필요는 없습니다. 엑셀에는 수를 한글로 나타내는 기능이 있기 때문입니다. 이 기능을 이용해야 엑셀에서 숫자로 취급합니다. 수를 입력한 후 마우스 우클릭해서 을 엽니다. 범주에서 를 선택한 후 형식에서 ...
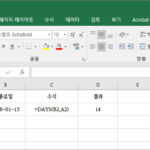
엑셀 / 함수 / DAYS / 두 날짜 사이의 일수를 계산하는 함수
개요 DAYS 함수는 두 날짜 사이의 일수를 반환하는 함수입니다. 구문 DAYS(end_date, start_date) end_date : 필수 요소로, 끝나는 날짜입니다. start_date : 필수 요소로, 시작하는 날짜입니다. 끝나는 날짜를 앞에, 시작하는 날짜를 뒤에 입력한다는 것에 주의합니다. 끝나는 날짜가 시작하는 날짜보다 이전이면 음수를 반환합니다. 예제 2018년 1월 1일부터 2018년 1월 15일까지의 일수를 계산하는 예제입니다. 만약 수식에 날짜를 직접 입력하고 싶다면 날짜를 따옴표로 감쌉니다. =DAYS("2018-01-15","2018-01-01")
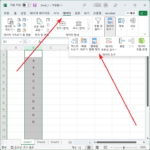
엑셀 / 중복된 값 찾는 방법, 중복 항목 제거하는 방법
엑셀로 자료를 취합하고 정리하다보면 중복된 값들이 생기기도 합니다. 그런 중복 항목을 찾기 위해 눈으로 검토할 필요는 없습니다. 엑셀에는 중복된 항목을 찾거나, 찾아서 제거하는 기능이 있기 때문입니다. 중복 값 찾기 중복 값을 찾을 열을 선택합니다. 을 클릭합니다. 을 클릭하면... 중복된 값이 강조됩니다. 조건부 서식에서 를 ...
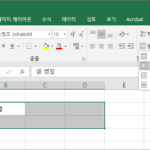
보기 좋게 표를 만들거나 보고서를 만들려면 셀들을 합쳐야 할 때가 있습니다. 엑셀에서는 셀을 합치는 것을 병합이라고 하고, 다시 나누는 것을 분할이라고 합니다. 어떻게 병합하고 분할하는지, 병합에는 어떤 방법이 있는지 알아보겠습니다. 병합하고 가운데 맞춤 셀을 합치는 가장 간단한 방법은 합치려는 셀들을 선택하고 을 클릭하는 것입니다. 셀들이 하나도 합쳐지고, 텍스트는 가운데 정렬합니다. 셀 병합을 하면 ...
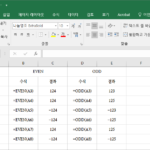
엑셀 / 함수 / EVEN, ODD / 짝수 또는 홀수로 올림 또는 내림하는 함수
개요 EVEN은 짝수로 만드는 함수, ODD는 홀수로 만드는 함수입니다. 구문 EVEN(number) ODD(number) 양수인 경우 가까운 짝수 또는 홀수로 올림하고, 음수인 경우 가까운 짝수 또는 홀수로 내림합니다. 예를 들어 EVEN(123) 은 123에서 가까운 짝수로 올림한 값 124를 반환합니다. EVEN(-123) 은 -123에서 가까운 짝수로 내림한 값 -124를 반환합니다. 즉, 인수가 부호만 차이난다면 결과도 부호만 차이납니다. 인수가 소수인 경우 정수를 반환합니다. 예를 들어 EVEN(122.1) 은 124를 ...
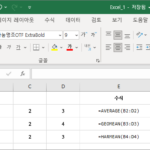
엑셀로 산술평균, 기하평균, 조화평균을 구할 수 있습니다. 사용하는 함수는 다음과 같습니다. 산술평균 : AVERAGE 기하평균 : GEOMEAN 조화평균 : HARMEAN 아래는 각각의 평균을 구하는 간단한 예제입니다. 아래는 위 예제에 대한 수식입니다.
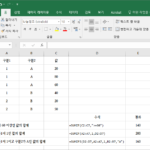
엑셀 / 함수 / SUM, SUMIF, SUMIFS / 합계 구하는 함수
개요 SUM은 합을 구하는 함수이다. SUMIF와 SUMIFS는 조건에 맞는 값들의 합계를 구하는 함수이다. SUMIF는 조건이 하나일 때 사용하고, SUMIFS는 조건이 여러 개일 때 사용힌다.(조건이 하나일 때 SUMIFS를 사용해도 된다.) 구문 SUM SUM(number1, , ...) number1 : 필수 요소로, 합하려는 첫 번째 숫자 또는 범위 number2, ... : 선택 요소로, 합하려는 추가 숫자 또는 범위 SUMIF SUMIF(range, criteria, ) range : 필수 ...
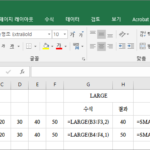
엑셀 / 함수 / LARGE, SMALL / k번째로 큰 값, 작은 값 구하는 함수
개요 LARGE는 데이터 집합에서 k번째로 큰 값을 반환하는 함수입니다. SMALL은 데이터 집합에서 k번째로 작은 값을 반환하는 함수입니다. 구문 LARGE(array,k) SMALL(array,k) array : 필수 요소로, 데이터 집합입니다. k : 필수 요소입니다. 몇 번째로 큰 값 또는 작은 값을 찾을지 정합니다. 예제 예제 1 10, 20, 30, 40, 50 중에서 2번째로 큰 값 또는 작은 값을 구합니다. 예제 2 10, 20, 30, 40, 50 중에서 첫 ...
자료 분석을 위해서 필터를 하거나 새롭게 수식을 만드는 것은 번거로운 일입니다. 피벗 테이블을 이용하면 다양한 형식의 분석 결과를 쉽게 만들 수 있습니다. 피벗 테이블을 만드는 방법은... 방법 1 분석하려는 자료를 선택한 다음, 을 클릭합니다. 만약 자료가 표라면 자동으로 표가 선택됩니다. 을 클릭하면... 새 워크시트에 피벗 테이블이 만들어집니다. 자료가 표가 아닌 경우 셀들을 선택해서 ...