엑셀 / 여러 워크시트 한 화면에서 동시에 보기
여러 워크시트 동시 작업
여러 워크시트에서 동시에 작업할 때가 있습니다. A 시트에서는 데이터를 관리하고, B 시트에서는 그 데이터를 분석하고...
작업을 하면서 여러 시트를 왔다갔다 하는 게 많이 불편합니다. 그럴 땐 한 화면에서 여러 시트를 한 번에 볼 수 있게 만들면 좋습니다. 시트간 이동도 편하고, 한 눈에 모든 걸 볼 수 있는 것도 편합니다.
여러 워크시트 동시에 보기
여러 워크시트를 동시에 보려면, [보기]에서 [새 창]을 클릭합니다.
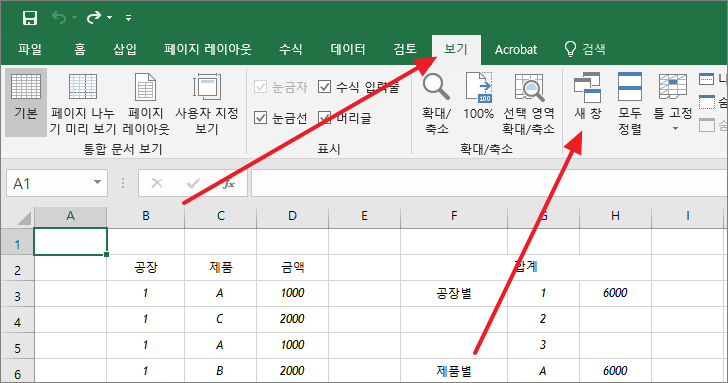
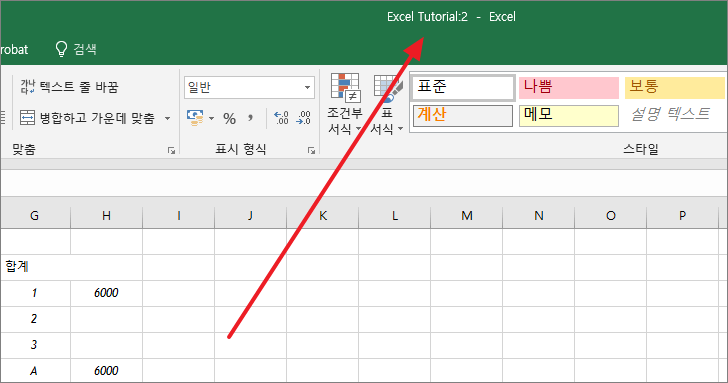
똑같은 내용을 가진 엑셀 문서가 하나 만들어집니다. 이름에는 일련번호가 붙습니다.
예를 들어 원래 문서의 이름이 Excel Tutorial이었다면, 원래 문서의 이름은 Excel Tutorial:1로, 새로 만들어진 문서의 이름은 Excel Tutorial:2가 됩니다.
편의상 번호가 붙은 것일뿐 파일 이름 자체가 바뀐 것은 아닙니다.
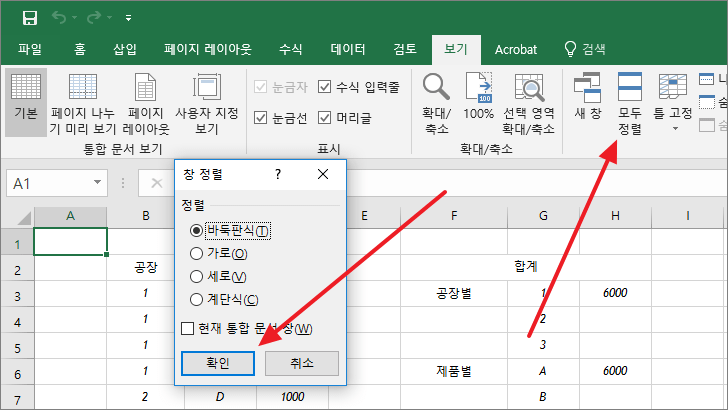
이제 [모두 정렬]을 클릭하면 창이 하나 뜨는데, 원하는 모양을 선택하고 [확인]을 클릭합니다.
두 개의 워크시트를 한 눈에 볼 수 있습니다. 서로 같은 파일이므로, 왼쪽에서 변경한 것은 오른쪽에도 반영됩니다.
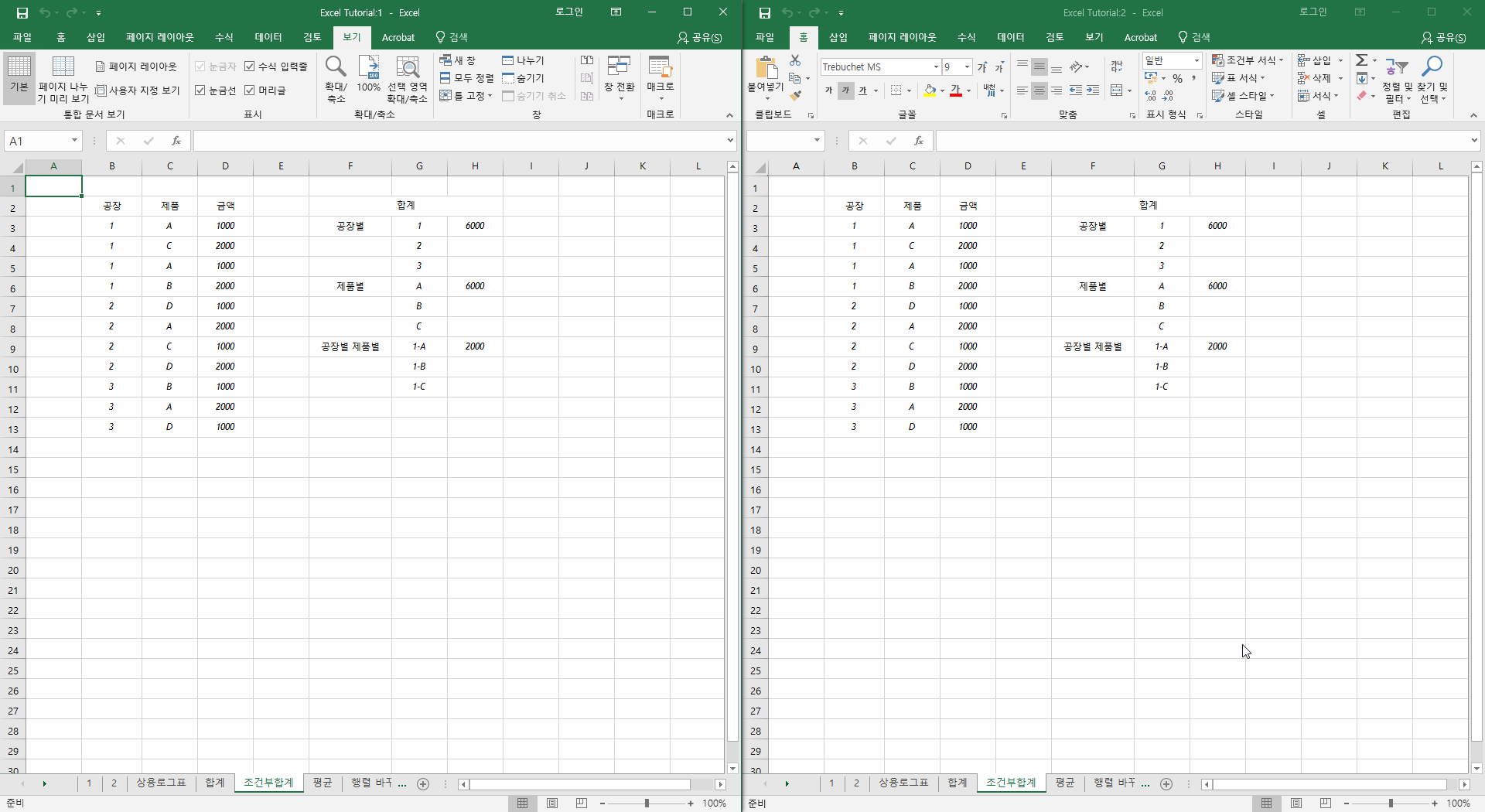
다음처럼 창을 더 많이 만들어서 사용할 수도 있습니다.
엑셀 / 양수(이익)를 빨간색, 음수(손실)를 파란색으로 만드는 방법
음수를 빨간색으로 강조하는 것은 셀 서식에 정의되어 있다. 숫자 형식으로 하고 음수의 표시 방식을 정하면 된다. 1000 단위 구분 기호도 쉽게 넣을 수 있다. 음수를 빨간색으로 표시하는 게 일반적이기는 한데, 국내 주식은 그렇지 않다. 오르는 게 빨간색, 내리는 게 파란색이다. 상승은 빨간색이라는 게 익숙해서, 엑셀에 손익을 기록할 때 손실이 빨간색으로 나오는 ...
엑셀에서 VBA, 매크로 작업을 할 때 메뉴에 개발 도구가 있는 것이 편합니다. 그런데, 기본 설정은 개발 도구 메뉴를 보이지 않는 거라, 메뉴에 추가하기 위해서는 옵션을 수정해야 합니다. 상단 왼쪽의 을 클릭합니다. 왼쪽 아래에 있는 을 클릭합니다. 을 클릭합니다. 을 클릭합니다. 이제 메뉴에 개발 도구가 보입니다. 메뉴 구성은 다음과 같습니다.
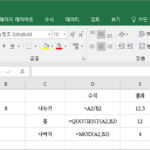
나누기 나누기는 슬래시 기호로 해요. 예를 들어 6 나누기 2는 6/2 와 같이 하면 됩니다. 몫 구하기 나누었을 때의 몫만 구하고 싶다면 QUOTIENT 함수를 이용하면 돼요. QUOTIENT(numerator, denominator) numerator에는 피제수, denominator에는 제수를 넣습니다. 나머지 구하기 나누었을 때의 나머지만 구하고 싶다면 MOD 함수를 사용합니다. MOD(number, divisor) number에는 피제수, divisor에는 제수를 입력합니다. 예제 다음은 100을 8로 나누어보고, 몫을 구하고, 나머지를 구하는 예제입니다.
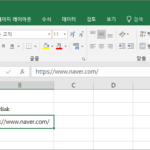
엑셀 / 하이퍼링크 제거하는 방법, 자동 하이퍼링크 안 생기게 하는 방법
자동 하이퍼링크 엑셀에 값을 입력할 때, 그 값이 URL이라면 자동으로 하이퍼링크가 생깁니다. 그리고 글자 모양과 크기는 기본 글자 모양으로 바뀝니다. 아래가 그 예입니다. 글자 모양은 나눔명조, 글자 크기는 10인 상태에서 네이버 URL을 입력했습니다. URL에는 링크가 만들어지고, 글자 모양은 맑은 고딕, 글자 크기는 11로 바뀌었습니다. 하이퍼링크의 기본 기능이 그 주소로 이동하는 것이므로, URL에 자동으로 ...
눈금선 엑셀의 시트에는 선이 있어요. 모니터에만 나오고 인쇄할 때는 나오지 않는 선이에요. 이 선을 눈금선이라고 합니다. 눈금선이 있는 이유는 셀의 위치를 파악하기 쉽게 하려는 거에요. 눈금선 없이 한동안 써봤는데 꽤 불편하더군요. 눈금선이 있는 게 좋아요. 그런데, 눈금선이 있는 게 더 불편한 경우가 있어요. 바로 모양을 꾸밀 때에요. 인쇄용 보고서를 만들기 위해 선을 그리고 ...
개요 ABS 함수는 'absolute value'의 약자로, 숫자의 절댓값을 구하는 함수입니다. 절댓값은 숫자의 크기만을 나타내며, 부호를 무시합니다. 예를 들어, -5의 절댓값은 5이고, 5의 절댓값은 그대로 5입니다. 구문 ABS(number) number: 절댓값을 구하고자 하는 숫자입니다. 이 인수는 숫자 자체일 수도 있고 셀 참조나 수식의 결과일 수도 있습니다. 예제 기본 예제 절댓값을 구하고자 하는 숫자를 직접 함수에 입력하는 방법입니다. 다음은 25를 반환합니다. =ABS(-25) 다음은 ...
엑셀 / 메모 삽입하는 방법, 메모 삭제하는 방법, 메모 일괄 삭제하는 방법
엑셀의 메모 기능을 이용하면 셀에 대한 설명을 남길 수 있습니다. 복잡한 계산을 했거나 공동 작업을 할 때 유용한 기능입니다. 어떻게 메모를 삽입하고 삭제할 수 있는지 알아보겠습니다. 메모 삽입하는 방법 메모를 삽입하고자 하는 셀에 마우스를 올리고 우클릭을 합니다. 팝업 메뉴에서 을 클릭합니다. 메모 삽입 단축키는 입니다. 포스트잇처럼 생긴 작은 창이 생기고, 그 ...
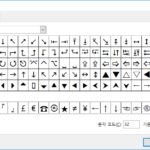
엑셀에 기호 또는 특수 문자를 입력하는 방법은 두 가지가 있습니다. 삽입 - 메뉴 상단에서 를 클릭합니다. 글꼴을 바꾸가면서 필요한 기호를 찾습니다. 기호를 선택한 후 을 클릭하면 기호가 셀에 삽입됩니다. 자음 + 한자 ㄱ, ㄴ 등 자음을 입력하고 한자 키를 누릅니다. 그러면 특수 문자가 나옵니다. 화살표를 클릭하면 입력할 수 있는 기호를 ...
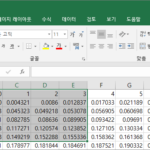
엑셀 / 인쇄 / 워크시트에서 선택한 영역만 인쇄하는 방법
엑셀은 선택한 영역만 인쇄하는 기능을 갖고 있습니다. 일부분만 인쇄하기 위해서 새로 시트를 만들 필요가 없습니다. 인쇄하고 싶은 셀들을 선택합니다. Ctrl+P를 눌러서 인쇄 창을 엽니다. 그리고 를 선택합니다. 미리보기에서 어떻게 인쇄가 되는지 볼 수 있습니다. 설정을 마쳤으면 를 클릭하여 출력합니다.
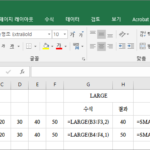
엑셀 / 함수 / LARGE, SMALL / k번째로 큰 값, 작은 값 구하는 함수
개요 LARGE는 데이터 집합에서 k번째로 큰 값을 반환하는 함수입니다. SMALL은 데이터 집합에서 k번째로 작은 값을 반환하는 함수입니다. 구문 LARGE(array,k) SMALL(array,k) array : 필수 요소로, 데이터 집합입니다. k : 필수 요소입니다. 몇 번째로 큰 값 또는 작은 값을 찾을지 정합니다. 예제 예제 1 10, 20, 30, 40, 50 중에서 2번째로 큰 값 또는 작은 값을 구합니다. 예제 2 10, 20, 30, 40, 50 중에서 첫 ...